In einer modernen IT-Landschaft ist es entscheidend, dass die Systeme und Anwendungen nicht nur funktionieren, sondern dass auch frühzeitig Trends und Potentiale zur Optimierung und Verbesserung erkannt werden.
Damit dies möglich ist, muss das IT-System eine wichtige Eigenschaft besitzen: Observability.
Was ist Observability?
Observability ist nicht einfach ein neues Modewort für Monitoring, die beiden Bereiche unterscheiden sich. Im Monitoring erkenne ich, wenn etwas nicht in Ordnung ist. Die Observability kommt vom englischen Begriff „observe“, auf Deutsch „beobachten“, und ist eine Übermenge des Monitorings. Observability führt die zum Monitoring erstellten Metriken, Protokolle, Traces und andere Telemetriedaten nahezu in Echtzeit zusammen, stellt sie visuell sowie übergreifend dar und erlaubt so Einblicke in den internen Zustand der Anwendungen und der Infrastruktur. Durch die Kombination von Monitoring und den Einsatz von entsprechenden Tools kann also Observability erreicht werden.
Für wen ist Observability relevant?
Observability ist vielmehr ein Attribut eines Systems und besonders für DevOps-Teams relevant, um den Überblick über komplexe verteilte Systeme zu behalten. In diesen können einzelne Komponenten auf mehreren Server, Rechenzentren und Cloud-Anbietern verteilt sein – wie es in mittleren und großen Unternehmen häufig der Fall ist. In solchen Umgebungen ermöglichen Observability-Tools wie Azure Monitor einen ganzheitlichen Blick auf das System und identifizieren und diagnostizieren Probleme über das gesamte System hinweg.
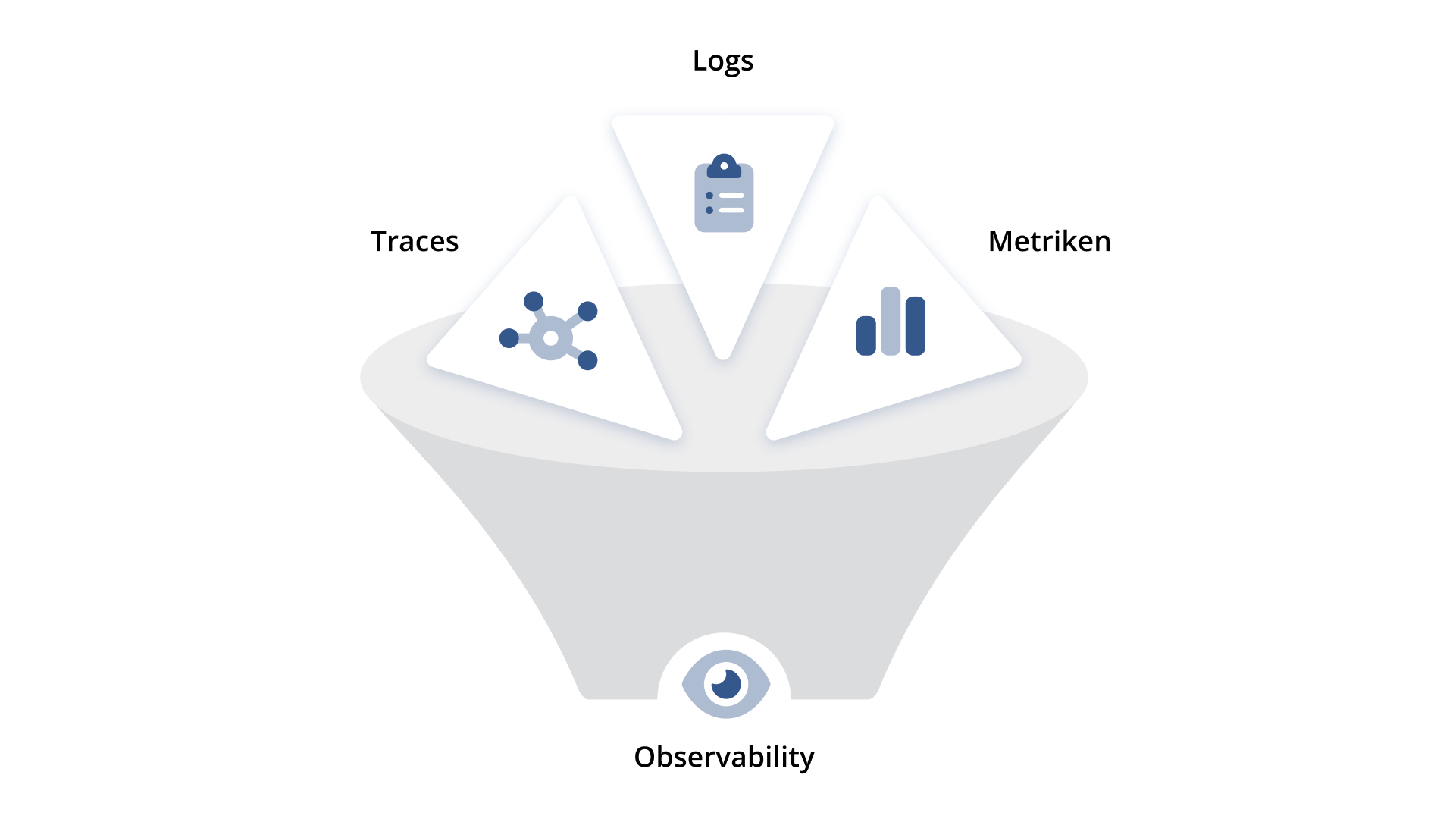
Die drei Säulen von Observability
Um ein übergreifendes Verständnis von Observability zu erhalten, sollten die folgenden drei Ressourcen betrachtet werden. Diese werden auch als die Säulen der Observability bezeichnet:
- Logs:
Ein Datensatz darüber, was gerade innerhalb der Software passiert.
- Metriken:
Eine numerische Bemessung der Anwendungsleistung und des Ressourcenverbrauchs.
- Traces:
Englisch für „Spuren“, so kann der Weg einer Anfrage durch das System verfolgt werden.
Die Fähigkeit, diese Daten über mehrere Systeme hinweg zu erfassen, wird als Telemetrie bezeichnet.
Logs
Eine gute Observability beginnt in der Anwendungsentwicklung. Der eigene Programmcode muss ein sauberes strukturiertes Logging besitzen und relevante Ereignisse, Fehler und Metriken protokollieren. Die Logs werden zentral, z. B. in Azure Monitor, abgelegt, wo diese mit anderen Signalen kombiniert werden können.
Metriken
Moderne Systeme stellen eine Vielzahl an Metriken bereit, um wichtige Aspekte wie Leistung, Auslastung, Antwortzeiten und andere relevante Informationen zu überwachen. Diese werden ebenfalls zentral über längere Zeiträume in Azure Monitor erfasst, um anhand dieser Zahlen Trends zu erkennen.
Traces
Über Traces lassen sich Anfragen Ende zu Ende durch das System verfolgen und Abhängigkeiten zwischen den Services und der Infrastruktur aufzeigen.
Observability vs. Monitoring: Der Unterschied
Beim Monitoring werden vorher definierte Daten aus dem betrachteten System gesammelt und analysiert, um diese zum Beispiel in einem Dashboard anzuzeigen. Diese Dashboards visualisieren die von den jeweiligen Entwicklern erwarteten Anomalien und Performance-Indikatoren. Allerdings bleiben dabei unvorhergesehene Probleme möglicherweise unter dem Radar und werden gar nicht oder erst viel zu spät erkannt.
Observability führt Logs, Traces und Metriken aus der kompletten IT Infrastruktur zusammen. Während das Monitoring einfach nur Daten anzeigt, ermöglicht die Observability den Infrastruktur- und DevOps-Teams alle Eingaben und Ausgaben über mehrere Anwendungen, Mikrodienste, Programme, Server und Datenbanken hinweg, übergreifend zu messen, zu verfolgen und zu analysieren.
Warum ist Observability wichtig?
Durch die konsolidierte Überwachung können IT-Teams Anomalien frühzeitig erkennen und proaktiv handeln, bevor sie zu ernsthaften Problemen wie schlechter Performance oder kompletten Downtimes im Unternehmen führen. Indem die Beziehungen zwischen den einzelnen Systemen verstanden werden, bietet Observability handlungsrelevante Einblicke in die Gesundheit des Systems und erkennt Fehler oder verwundbare Angriffsvektoren beim ersten Anzeichen abnormaler Performance. Sollte es bereits zu einem Problem gekommen sein, können IT-Teams auf Basis der zusammengeführten Daten den Vorgang detailliert analysieren und Lösungen finden. Letztlich geht es darum, die Softwarelandschaft stabil, nutzbar und leistungsfähig zu halten.
Wir unterstützen Unternehmen bei der Auswahl, Implementierung und beim Betrieb der für ihre Bedarfe passenden Lösung, beispielsweise basierend auf Standardsoftware wie Azure Monitor.
Azure-Ressourcen generieren eine erhebliche Menge an Überwachungsdaten. Das Zusammenführen der Daten aus allen Quellen innerhalb und außerhalb von Azure in einen Arbeitsbereich ist die Stärke von Azure Monitor.
Mit Azure Monitor und den eingebauten Tools lassen sich umfassende Funktionen umsetzen:
- Systemzustand in Echtzeit überwachen
- Daten mit Azure Log Analytics und KQL (Kusto Query Language) abfragen
- Benachrichtigungen und Alarme erstellen
- Daten von unterschiedlichen überwachten Ressourcen sammeln
- Dashboards und Ansichten erstellen, um den Zustand und das Verhalten von Ressourcen zu visualisieren.
- Workbooks für die Datenanalyse und die Erstellung umfassender visueller Berichte verwenden. Workbooks sind interaktiv und können teamübergreifend mit Datenaktualisierungen in Echtzeit freigegeben werden.
- Automatische Reaktionen umsetzen, um entweder das System zu skalieren oder mit Azure Logic Apps
automatisierte Workflows auszuführen.
Azure Monitor kann in Kombination mit Microsoft-Lösungen, Open-Source- und Partnerlösungen arbeiten. Der Vorteil: IT-Teams können die Observability bei Bedarf um zusätzliche Systeme und Anwendungen erweitern und über alle hinweg operieren. Deshalb unterstützen Azure Monitor und alle Azure SDKs OpenTelemetry als herstellerneutralen OpenSource-Standard und integrieren sich nahtlos mit offenen APM-Systemen, wie Prometheus, Grafana, Jaeger und Zipkin aber auch kommerziellen Lösungen.
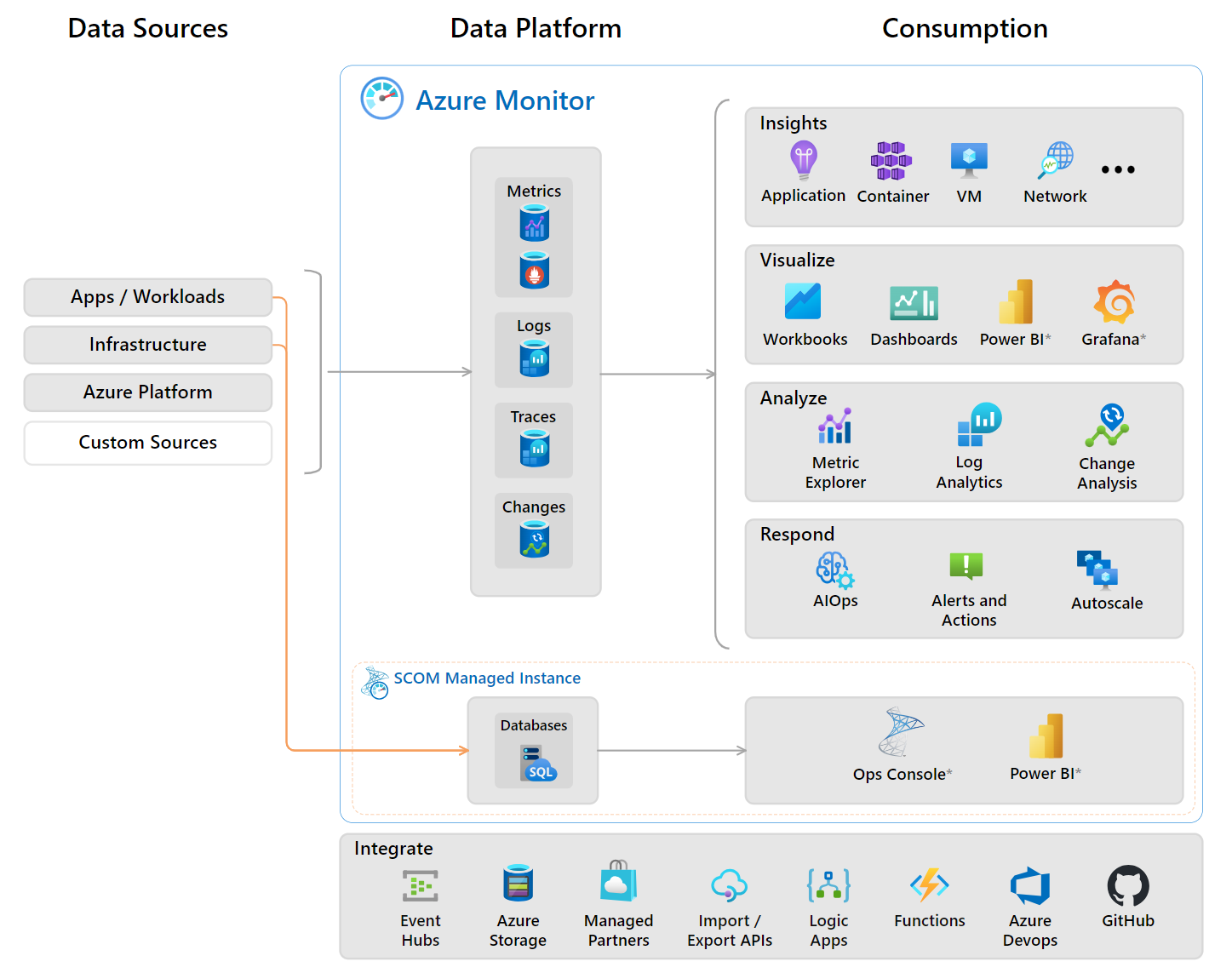
Quelle: Azure Monitor – Übersicht | Microsoft Learn
Mit der Azure-Monitor-Komponente AIOps kann maschinelles Lernen genutzt werden, um aus den in Azure Monitor gesammelten Daten „Wissen“ über die Systeme zu erlangen. Mit diesem Wissen kann die künstliche Intelligenz (KI) Trends und potenzielle Probleme erkennen, diagnostizieren und im besten Falle vorhersagen.
Observability als Teil des Software-Entwicklungsprozesses
Um eine gute Observability zu erreichen, muss diese in allen Schritten im Lebenszyklus einer Anwendung eine Rolle spielen und von den Entwicklern und dem DevOps-Team als Mittel zur Erstellung von zuverlässiger Software verstanden werden.
Das beginnt bei der Architektur der Lösung und dem Entwicklungsprozess: Dort muss die Bereitstellung der entsprechenden Telemetriedaten initial umgesetzt werden und zwar nach vorgegebenen Standards in allen Komponenten.
Während des Betriebs muss beim Auftreten einer Anomalie ein entsprechender Alert ausgelöst werden, welcher dann zu einem Incident führt, falls es zu einer Beeinträchtigung des Systems bzw. der Stakeholder kommt.
Diese Zwischenfälle und Systemausfälle müssen im Nachhinein im Rahmen von Retrospektiven oder Postmortems analysiert und die Ergebnisse wieder in die Verbesserung des bestehenden Monitorings sowie in die kontinuierliche Weiterentwicklung der Anwendung einfließen.
Dieser Prozess wird oft auch als Observability Engineering bezeichnet.
Observability: Wie komme ich an Telemetriedaten?
Telemetriedaten ermöglichen Monitoring und Monitoring ermöglicht Observability.
Doch wie kommen Unternehmen an diese Telemetriedaten? Dazu müssen Entwickler in den folgenden Bereichen Hand anlegen:
Logging
Logging dient dazu, wichtige Ereignisse, Zustände und Fehler während der Laufzeit einer Anwendung zu dokumentieren. Der Grundsatz „viel hilft viel“ wäre hier fehl am Platz, denn wahlloses Logging kann ressourcenintensiv und teuer sein. Stattdessen sollten Unternehmen gezielt loggen und dazu definieren, welche Ereignisse, Zustände und Fehler während der Laufzeit einer Anwendung als relevant eingeschätzt und dokumentiert werden sollen.
Logs sollten in allen Anwendungen dasselbe, am besten versionierte Schema verwenden. Das bedeutet, ein Log-Eintrag sieht in allen Schichten der Anwendung gleich aus und nutzt immer gleichbedeutende Log-Level. Am besten wird nur ein produktives Log-Level und „Debug“ während der Entwicklung genutzt.
Instrumentierung
Jede wichtige Kennzahl (Metrik) in einer Anwendung oder einem Dienst sollte erfasst werden. Dazu muss der Anwendung unter Umständen ähnlich wie beim Logging entsprechender Code hinzugefügt werden, um diesen zur Laufzeit zu erfassen. Ein Beispiel: Eine Anwendung kommuniziert mit einer Datenbank und nutzt dazu einen Connection-Pool. Hier ist es wichtig, die Größe dieses Pools und die Anzahl der ungenutzten Verbindungen zu einem bestimmten Zeitpunkt zu verfolgen. Dazu muss der Entwickler einige Codezeilen in die Logik des Verbindungspools einfügen, um zu verfolgen, wann genau Verbindungen erstellt oder geschlossen, wann sie vergeben und wann sie wieder zurückgegeben werden.
Automatische Warnungen und Alarme
Bei der Entwicklung müssen vom Team für bereits erwartete Schwellenwerte oder kritische Ereignisse bereits Benachrichtigungen vorgesehen werden. Diese bilden die Basis für das initial bereitgestellte Alerting der Anwendung und werden während des Betriebs stetig ausgebaut.
Echtzeit-Verarbeitung
In modernen Cloud-Infrastrukturen erzeugen nicht nur Entwickler in der Software Metriken, sondern automatisch auch die eingesetzten Komponenten. Hier muss dafür gesorgt werden, dass diese ebenfalls z. B. an Azure Monitor gesendet werden, um diese persistieren und nutzen zu können. So kann die Leistung und der Systemzustand inklusive der Komponenten in Echtzeit überwacht werden.
Dokumentation
Als Teil des Entwicklungsprozesses müssen die Instrumentierung, Metriken und Protokolle ausführlich dokumentiert werden, um sicherzustellen, dass andere Entwickler und Betreiber die gesammelten Daten verstehen und effektiv nutzen können.
Observability & Security: Azure Sentinel
Observability ist nicht nur im Anwendungskontext relevant, sondern ebenso im Security-Bereich. In diesem Fall werden die Traces, Logs und Metriken zentral in einem Security Information and Event Management System (SIEM-System), wie z. B. Azure Sentinel, zusammengeführt. So können IT-Teams innerhalb dieses Systems Anomalien erkennen und Sicherheitsvorfälle analysieren.
Azure Sentinel und Azure Monitor setzen dabei auf denselben Unterbau und ermöglichen auf Grund derselben Tools und Techniken eine besonders einfache und übersichtliche Überwachung von Sicherheit und Funktionalität, insbesondere bei komplexen Incidents.
Als Dienstleister zur Implementierung und Vernetzung von Cloud-Analytics-Plattformen
und Cloud-Security-Systemen
unterstützen wir Unternehmen von der Beratung und Konzeption bis zur Umsetzung und zum Betrieb von Monitoring- und Oberservability-Lösungen.
Jetzt in einem kostenlosen Erstgespräch informieren!




