Identity Governance – The life cycles
When I talk about Identity Governance, I focus on three main “life” cycles:
- Identity: The whole lifecycle of a user in a company. In our words the standard “Starter, Changer, Leaver” processes (E.g., a user is hired in a company, changes department or leaves the company).
- Access: All access related actions within the user life cycle based on e.g., job changes.
- Privileged access: Admin rights on services and resources which are not needed the whole time and are mostly safety critical.
Each of these life cycles are part of every company, in more or less complex environments. In this blog series I want to describe the basics on each of the cycles, in a cloud first approach. So, we focus on the governance areas in Azure and what currently is the state-of-the-art components. In this first blog post the focus is on the Identity Management and basically on these key aspects:
- Compare of current on-premises IDM solution and cloud first approach
- Main aspects regarding a cloud first solution with the provisioning service
Architecture on-premises vs. cloud first (MIM vs. Provisioning Service)
Identity Management builds the basis for the configuration and living of the access management lifecycles. In the best case all relevant processes are implemented in an automated way and resolve in consistent accounts over all central applications (in our scenarios mainly Active Directory and Azure Active Directory). So all Starter, Changer and Leaver processes are covered and accounts have at any time the most recent data on them.
Data is primary maintained in HR systems like SAP and transferred via different solutions to Microsoft AD’s. In the most current scenarios, the Microsoft Identity Manager is the single point of truth for all of the internal and external user accounts and secures the adherence to the compliance guidelines. An architecture can look like this:
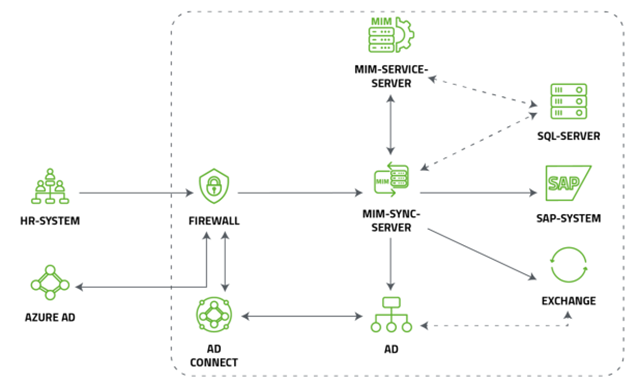
The data, centralized managed in an HR System, is synchronized via MIM-Sync-Server to AD, SQL, and other systems like SAP to create and maintain for every user a single account. Additionally in most scenarios the MIM-Service-Server (MIM Portal) is used to built up workflows and rules to maintain the accounts to reflect all IDM related processes of the company.
This architecture has a huge focus on on-premises and the transfer to a cloud first approach with Azure is a main topic in the current time. To provide these synchronization functionalities the Azure AD Provisioning Services is the current solution in Azure instead of using MIM. The architecture could look like this nowadays (in a hybrid scenario with a leading AD system on-premises):
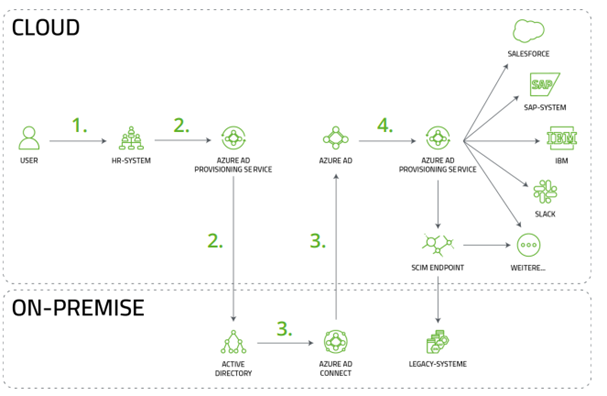
You can also find a more detailed explanation of this scenario in our solution paper.
.
In this architecture the main focus is in the cloud and the generation of hybrid accounts. They are synchronized by the provisioning service to AD and afterwards via Azure AD Connect to the cloud. After that there is the possibility to user another Service or SCIM endpoints to export the data to the related target systems.
For cloud only accounts the provisioning service also can be used to achieve a direct synchronization between the HR-system and Azure AD:
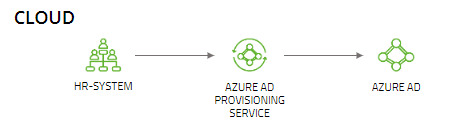
Important restriction currently is, that the provisioning service can only be integrated with SAP SuccessFactors and Workday (status 01.01.22). Microsoft is currently also working on more integration possibilities like CSV file processing or direct REST API usage. But in the current state only the Workday and SuccessFactors applications can be found in the Azure AD Gallery:
Setup the provisioning service – The Sticking points
Basically, the provisioning services is an enterprise application which can be simply added via the Azure AD gallery. There are a few different applications for the main scenarios:
- HR-System to Active Directory on-premises for on-premises only or hybrid accounts
- HR-System to Azure Active Directory for cloud only accounts
- Azure Active Directory to HR-Systems for writeback scenarios (like mail where Azure is leading)
Next step is to configure the access to the HR-System and Active Directory or Azure on the other side. Especially for the on-premises synchronization to AD another component, the “Provisioning Agent”, is needed to transfer the outgoing requests from the service to the LDAP language of AD.
All these installation steps and configurations are well described in the existing documentation and work fine, so I want to give some dedicated input on interesting aspects within the service, based on the scenario “SAP SuccessFactors to Active Directory”:
Main work: Configuration
Instead of current solutions like MIM, Graph, PowerShell etc., the provisioning service is mainly a configurable service where VBA like functions, JSON expression for attribute definition and the UI in Azure Portal are used to define the whole synchronization. For example, a switch function can be used:
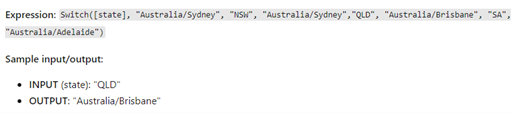
Therefore, it is a low-threshold entry to provide the basic functions and no deep knowledge of a dedicated coding language is necessary.
Use multiple services with Scoping
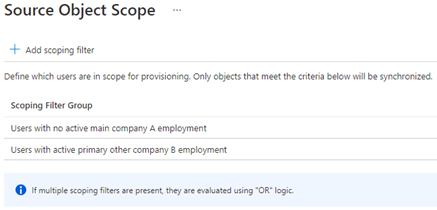
With the scoping mechanism based on dedicated HR attributes the service can be configured to synchronize only users which fall into that scope. So not only one enterprise application covers all of the processes, for example multiple services can be configured in parallel to solve scenarios:
- Service 1: Creation and Maintenance for all user accounts from company A to Active Directory
- Service 2: Creation and Maintenance for cloud only accounts based on specific attributes in Azure Active Directory
- Service 3: Termination of all user accounts who are not in company A anymore or switched to company B:
Understand the delivered data
A big effort at the beginning of the implementation of the provisioning service is the understanding of the HR data. As in the old architecture with MIM, it must be clear which data is delivered from HR and also in which quality.
SAP SuccessFactors for example can create own entity types or attributes which must be defined individual in the attribute mappings from the service. Also, the rights on these additional parameters must be set in the HR system so the service can access all of them correctly. A clear and direct communication with the HR colleagues at the beginning is therefore mandatory.
To test basically the rights and the delivered data from SAP SF a postman Environment can be built up to test in a fast way whether the access is granted for the specific users and to understand the data. A result JSON can look like this (extract):
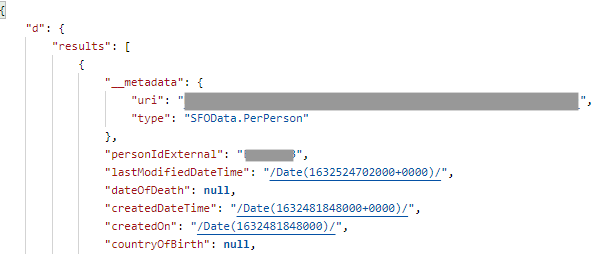
To send the request to SAP SF the following URL can be used. Additonally the „apiURL“ (SAP SF API URL), the filter „personIdExternal“ (The personIdExternal of the SAP SF account) and the authorizationHeader must be defined in Postman to send the request.
Besides that in the expand parameter all necessary entities from SAP SF must be set to get this entity in the result. The syntax is like a tree to navigate through the JSON. Like in the following request it starts with the „employmentNav“-entity, and the next leaf is the „userNav“-entity:
https://{{apiurl}}/odata/v2/PerPerson?$format=json&$filter=(personIdExternal in '{{personIdExternal}}')&$expand=employmentNav/userNav,employmentNav/jobInfoNav,
Logs and Testing
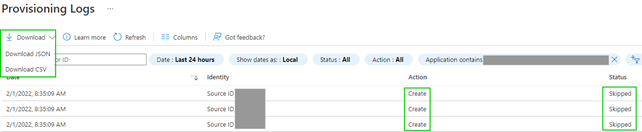
The log of the service gives a lot of information about what the service synchronizes or tries to do in AD. There is the option to “provisioning user on demand”, so on dedicated objects the implemented processes can be tested. But there is no preview functionality to have a full overview about what synchronizations will happen for the hundreds or thousands of accounts after the provisioning is activated.
A workaround for that is to remove the rights of the service (Create, Update, Delete) and run the synchronization for all accounts.
The service will try to synchronize the scoped accounts based on the implemented logic. These actions will be logged and e.g., for the skipped actions the logs can be downloaded and analyzed whether the creations are correct, and the rights can be granted:
Know the limitations
The provisioning service is currently under fast development (As of 01.02.22). Due to the basic limitation that you only can configure the application and not implement own code fragments there are some process limitations where workarounds must be implemented:
- Standard applications only available for SAP SuccessFactors and Workday
- Unique value generation only on create, so for example an overall name change process is not possible after creation
- Custom entities from SAP SuccessFactors can not be read from the service
- Customized code or extensions can not be implemented directly in the service (only usage of existing VBA like functions)
- NULL values are not processed, so no clearing of AD fields
- Only provision on demand for a single user is available, no preview for all changes which will happen in AD
Alternatives to covering these processes include scripts on the AD side, additional manual, and organizational steps, or moving on-premises logic to additional cloud services.
And now?
The provisioning service is in the current implementation not an overall solution for everyone. But for the basic IDM processes and especially when SAP SuccessFactors or Workday is in use it is a lightweight configurable solution to start the synchronization to Active Directory or Azure Active Directory. Microsoft is focusing this service currently and more features will be implemented soon.
Which automation gaps do you see in your IDM environment? Is a cloud first approach interesting and realizable for you? What features are missing in the provisioning service to start with an implementation?




