I attended the KubeCon - CloudNativeCon Europe 2024
in Paris recently and had the opportunity to hear a lot of great talks about cutting edge developments in the open source world.
A recurring theme was the challenge of using large language models (LLMs) in cloud applications.
In this post, I want to give an introduction to kaito, a Kubernetes operator that makes it easier to deploy LLMs in Azure.
Deploying Open-Source LLMs in Kubernetes
Anyone wanting to use LLMs first has to answer the question of whether to use a closed- or open-source model.
The “right” answer depends on the use case, governance requirements, money, needed flexibility, etc.
When the right answer is to use an open-source model, the big challenge is how to actually deploy it.
LLM workloads require provisioning specialty hardware and careful utilization of it to obtain good performance and control costs.
These workloads are highly variable; CPUs can handle some tasks, while others require GPUs or TPUs.
The proximity of the model files to the compute resources can have significant impact on latency.
Kubernetes lends itself well to these requirements.
Containers are framework-agnostic.
The specialty hardware needed for AI workloads is simpler to provision and configure compared to working directly with virtual machines.
Resource utilization can be optimized with auto-scaling of nodes and pods.
The process is similar to deploying any solution on Kubernetes:
Containerize the model and host the image, provision the compute infrastructure and configure scaling and load balancing, set up an inference server as an app endpoint service in Kubernetes, and then monitor and adjust.
But the devil, as always, is in the details; it takes time and there is a lot of trial and error.
The open-source Kubernetes AI Toolchain Operator
(Kaito) attempts to simplify the deployment of LLMs to Kubernetes clusters as much as possible.
Kaito offers the following benefits:
- automates deployment of LLMs, reducing the amount of manual configuration and maintenance effort needed,
- creates container images of large model files and publishes them in the public Microsoft Container Registry, if the license allows, simplifying model setup for the user so that the inference service can be set up more quickly,
- provides preset configurations for LLMs, optimizing performance on GPU nodes and removing the need for fine-tuning of deployment parameters for the nodes, and
- dynamically provisions GPU nodes based on model requirements and integrates with Azure Kubernetes Service for reconciling the current and desired state.
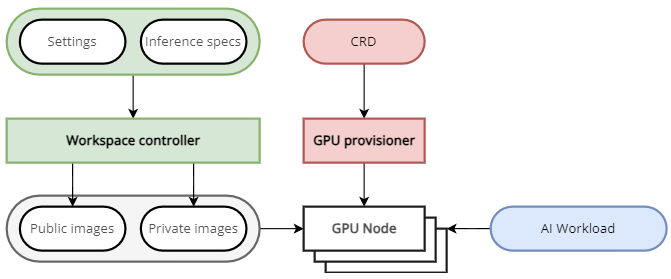
The operator consists of
- the
workspace customer resource definition (CRD), which defines the schema of settings a user can configure for GPU requirements and the inference specification. The user specifies the settings in a Workspace custom resource (CR). These components are represented in green in the image below.
- the
workspace controller, which reconciles the workspace customer resource configured by the user.
It creates GPU custom resources to trigger node auto-provisioning and creates the inference workload (either a Deployment or a Statefulset) based on the model present configurations, if a preset model is selected. More on presets later.
- the
gpu provisioner controller, an open-source component that adds new GPU nodes to the Azure Kubernetes Service cluster, based on the settings provided in the Node Provisioner CR (red components).
When the service is run, the GPU nodes are spun up, and the container images holding the model weights are pulled from either a public or private container registry, seen on the left of the diagram below.
Kaito hosts public models in the Microsoft container registry, and users can maintain private model images in their own private registry.
Workspace Custom Resource and preset Models
Let’s look at a simple Workspace CR to understand how to use Kaito to deploy an LLM and inference service.
apiVersion: kaito.sh/v1alpha1
kind: Workspace
metadata:
name: workspace-falcon-40b-instruct
resource:
instanceType: "Standard_NC96ads_A100_v4"
labelSelector:
matchLabels:
apps: falcon-40b-instruct
inference:
preset:
name: "falcon-40b-instruct"
In the resource section, the user can specify the resource requirement of running the workload.
The default configuration is to provision a Standard_NC12s_v3 virtual machine GPU node.
Kaito splits inferencing across multiple lower-GPU count virtual machines, which are cheaper and more readily available.
The inference section is used to configure the LLM against which predictions will be made.
To use a supported open-source model, configure a preset object.
In the example above, the open-source publicly-hosted LLM falcon-40b-instruct
is specified.
If the desired model is not available in the public registry, the user needs to manage the inference service images containing the model weights in their own private registry, but still benefits from the configurations that take care of parameter fine-tuning.
What if none of the supported preset models meet the current requirements?
Then the user can deploy their own containerized model and, instead of describing a preset object in the inference section, define a template, in which they specify the pod template to be used.
The Kaito operator minimizes a lot of the pain points of deploying open-source LLMs in a production environment.
A variety of open-source models are already supported
with presets, including llama-2, falcon, mistral and phi-2, and community users are encouraged to propose new models.
Additionally, as announced at KubeCon, there is a new public preview of the Kaito add-on for Azure Kubernetes Service
, making deployments to AKS even more streamlined.
If you’re interested to learn more, try it out or take a look at these resources from KubeCon Europe 2024:
Have fun deploying LLMs the easy way!
Objektkultur is a german software service provider and partner of Microsoft




